

Wordles are often used to convey the "essence" of a document by demonstrating the frequency of the occurrence of a word via the size in which it is printed. However, such conveyance is sometimes frustrated by occurrences of a variety of different forms of the same word -- singular versus plural, for instance. Thus, this website applies a simple text mining pre-processor (written in python) to the text before it is sent to wordle.net. You can see this pre-processing by clicking on the Preview button.
For example, the default text in the text area is a collection of statements about being a good teacher ( click Reload Example to recover the default). A wordle can be used to capture the essence of what these statements say about good teaching, but the default wordle approach treats "student" and "students" as two separate words (and also treats "know" and "knows" as two different words). The pre-processing removes common words and then uses a matching algorithm (more details below) to group words into related groups (called "tags"), after which the most frequent word for each group becomes the value of the tag. The Threshold parameter controls the sensitivity of the match (1.0 is strict -- all words are independent as per the usual approach -- while 0.0 means all words match each other and there is only one "tag" group). In this way, "student" and "students" fall into the same word group (i.e., have the same "tag"). The difference is illustrated by the two wordles below:
|
|
|
| Original Teaching Characteristics Wordle | A Teaching Characteristics Wordle with Clustering |
We use the same font, layout, and color scheme in both so that the two can be compared. The wordle with clustering combines the various forms of "know" -- among others -- to illustrate that (at least in this demonstration) a good teacher emphasizes her students, is understandable, and is always "in the know".
Similarly, a wordle on the constitution suffers from such small variations. The original and "clustered" wordles are shown below:
 |
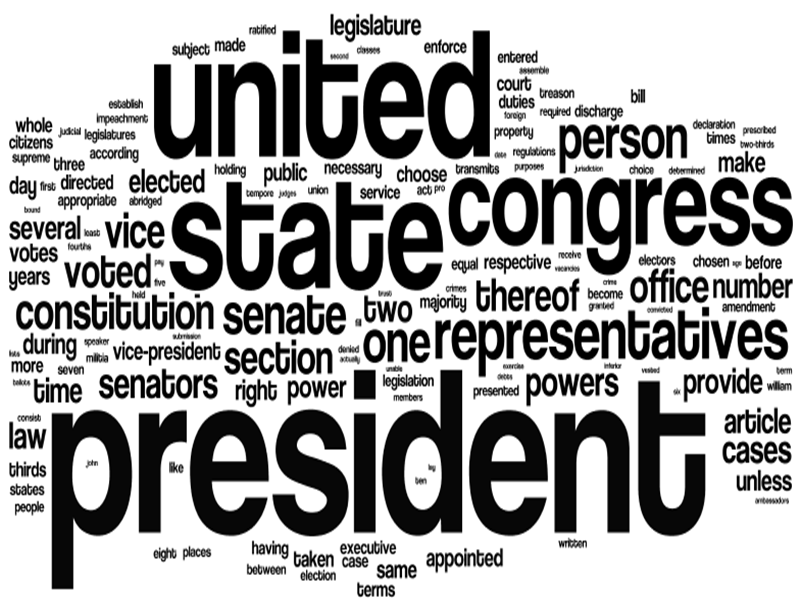 |
|
| Original US Constitution Wordle | A US Constitution Wordle with Clustering |
Finally, it is important to note that wordles cannot completely capture the essence of a document. Words are not individual patterns. Their meaning and interpretation varies -- most words have multiple definitions, in fact!! Consider, for example, the following sentence:
The law of the land says that an
airplane can land on land
owned by landed gentry as long as their own flying craft
land on their land and they don't own too many planes.
The sentence is clearly about airplanes and where they can land, but any wordle -- no matter how "scientific" or how much clustering is done -- would imply that the sentence is mostly about owning land. The problem is that the word "land" has many meanings, whereas airplane, flying craft, and planes are separate words referring to (mostly) the same "tag." This is typical in text-mining applications -- i.e., that such applications often need to reflect the conceptual context and variety of word usages, definitions in a way that differentiates even between a word and that same word used differently in another part of the document.
The pre-processing is based on the Levenshtein distance between two strings
(see
http://en.wikipedia.org/wiki/Levenshtein_distance and
http://en.wikipedia.org/wiki/Damerau%E2%80%93Levenshtein_distance for
details). Specifically, a fuzzy matching algorithm called
LevenMatch is defined which returns a relative comparison between two
strings a and b. The return value is in [0,1] and
LevenMatch( 'cat', 'bat' ) = 0
LevenMatch( 'cat', 'cats' ) = 0.5625
LevenMatch( 'student', 'students' ) = 0.765625
Any two words with a LevenMatch above the Threshold are put into the same "word group" (i.e., tag), and then the tag value is associated with the number of words in each word group.
__________
click here to download the python source file (and see source for this page).
Based on the excellent
 website located at http://www.wordle.net
and developed by Jonathan Feinberg.
website located at http://www.wordle.net
and developed by Jonathan Feinberg.
Email: knisleyj who is at etsu.edu.